
by Diego Freijo
Welcome to the first dispatch coming out of the Ministry of Silly Ideas! It’s a space we’ve got inside Anvil where we encourage ourselves to come up with interesting-even-if-sounding-silly-at-first-glance ideas around security or IT in general. We then filter out those ideas that might even work in real life and implement a proof-of-concept to see if they pass the reality check. And, who knows? Some of those ideas might even be not-so-silly after all!
The silly idea described in this blogpost is a tool we call Hominoid, a browser extension that alerts users to spoofed websites without using a centralized repository of malicious sites. It does so using perceptual hashing algorithms. The full source code of the extension can be found here: https://github.com/anvilsecure/hominoid.
Traditional Approach: Phishing Website Database
Phishing pages are all over the web. Google developed technologies to deal with this issue including a central database of sites marked as “malicious.” Centralization has obvious privacy implications. Google does attempt to preserve the privacy of its users; URLs sent to check against the central database are not sent in plain text.
There are issues with these kinds of third-party anti-phishing services:
- The user relies on Google maintaining the list properly.
- If the Google database is unreachable, the anti-phishing detection does not work.
- Any solution that works by centrally locating and flagging sites will be slow to catch new attacks. Until someone reports a phishing website to the centralized service, other users run the risk of being phished.
A Silly Idea Is Born
Another native solution might work analogously to virus scanners. A browser plugin could attempt to analyze a web page's HTML, CSS and JavaScript code and *somehow* attempt to figure out whether the code is malicious. Of course, this approach will never work perfectly due to a myriad of obfuscation possibilities and it again relies on a centralized database of *patterns flagged as malicious* similar to how anti-virus scanners work. It will always end up being a continuous cat-and-mouse game.
And this is the crux of our silly idea. Can we attempt to detect a phishing webpage without relying on a centralized repository? So we worked our way backwards from the very simple idea of what is happening when someone visits a phishing webpage. The phishing website *looks* exactly like the target website but the website URL won't match. A user *sees* a webpage that looks exactly the same as the one they *expect* to see, and is tricked into believing that it is the original website.
As such, can we create a piece of software that detects when a user sees a website very similar to what they expect to see but at a completely different domain?
The train of thought then turns to how to fix the centralization and privacy issues, then into “we need some sort of simple signature to identify a page.” And then of course perceptual hashing algorithms came into play.
Reusing Old Ideas
Assuming we have a decent algorithm to create a fingerprint of a webpage, we could use a solution similar to what OpenSSH does for fingerprinting. Upon the first time connecting to a website, SSH asks if the user still wants to connect to a host with a certain fingerprint. Then the fingerprint is added to the local database. Afterwards, when connecting to a host, SSH checks whether the site's fingerprint is similar to the one stored in the local database. If it does not match, it issues an error message as shown below. We can use this type of logic for any website containing a login form..

At this point, Hominoid logic departs slightly from SSH. For phishing detection, we would use a similar approach for websites the user hasn't visited before. If another website is similar to a fingerprint stored in our database, Hominoid could warn the user about a potential phishing attack.
To reiterate the core of the silly idea, can we come up with a fingerprint of a website which enables us to detect clones of websites that we’ve visited before? If the domains are different, we might be under a phishing attack! So how do we fingerprint websites?
Perceptual Hashing
A perceptual hashing algorithm takes an image as input and produces a 64-bits long signature of it. It works by removing as many variables from the input as possible. First by reducing its size, then by converting it to grey-scale, and finally by applying a simple function that converts each of the remaining pixels to a 1 or a 0. This final function changes depending on the exact algorithm used. The simplest algorithm takes the average of all pixels and marks as 1 those pixels above the average and marks the rest 0.
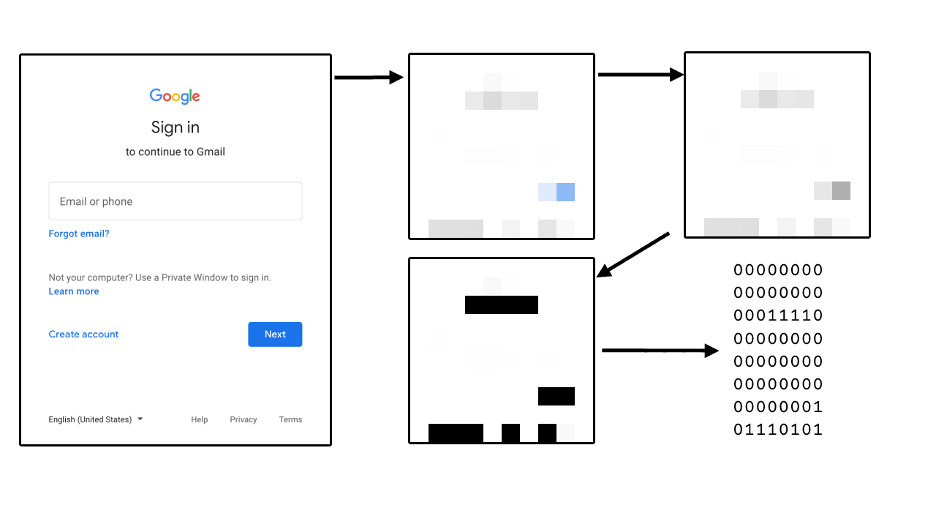
Using a perceptual hashing algorithm, Hominoid can take a screenshot of a page and store its signature in a local database. By doing this, we managed to emulate the SSH behavior described before.
Comparing Signatures
As opposed to cryptographically-secure hashing algorithms like MD5 or SHA1, when the input of a perceptual hash has a slight modification, its signature will also be slightly modified. Sometimes it will not be modified at all. This implies that if two signatures are similar, then their associated input images must be similar as well.
For example, on these two images of the Gmail login form, Hominoid can see how the signature changes just by removing the footer its signature changes.
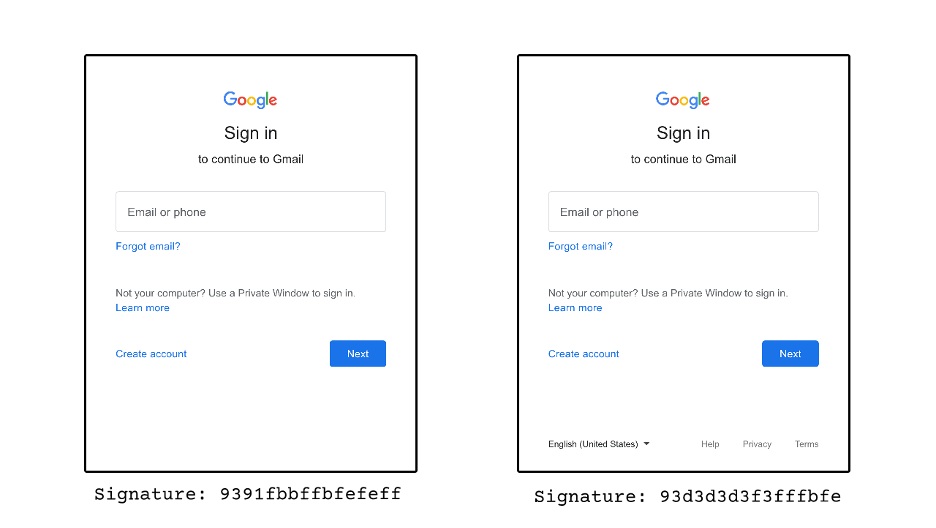
This reduces the complexity of the challenge faced when comparing two sites to just comparing two 64-bits long signatures. This comparison is the Hamming Distance, which simply counts the amount of bits that one hash differs from the other. If the distance is below a threshold, we consider the corresponding images as similar. With Hominoid, we tried a few different threshold values and found 10 to be a good balance. A higher value would mark very different pages as similar, and a lower one would miss similar pages.
Taking Screenshots
In theory, taking a page screenshot is an easy task. In practice, it was the most challenging part of this proof-of-concept. The issue is that each device where the extension runs could have a different resolution. Even on the same device, the browser window might be resized on different page visits. Hominoid needs each page screenshot to be the same, or the hashes comparison might fail even when comparing website screenshots from of the exact same resolution and size.
For our proof of concept, we went through the simplest solution we could find. Before taking a screenshot, Hominoid resizes the browser window to a fixed size. We choose 360x640, but any size might have worked. It works, but with a big drawback: on every page visit, the user will see the browser window flickering. It is not a user-friendly experience.
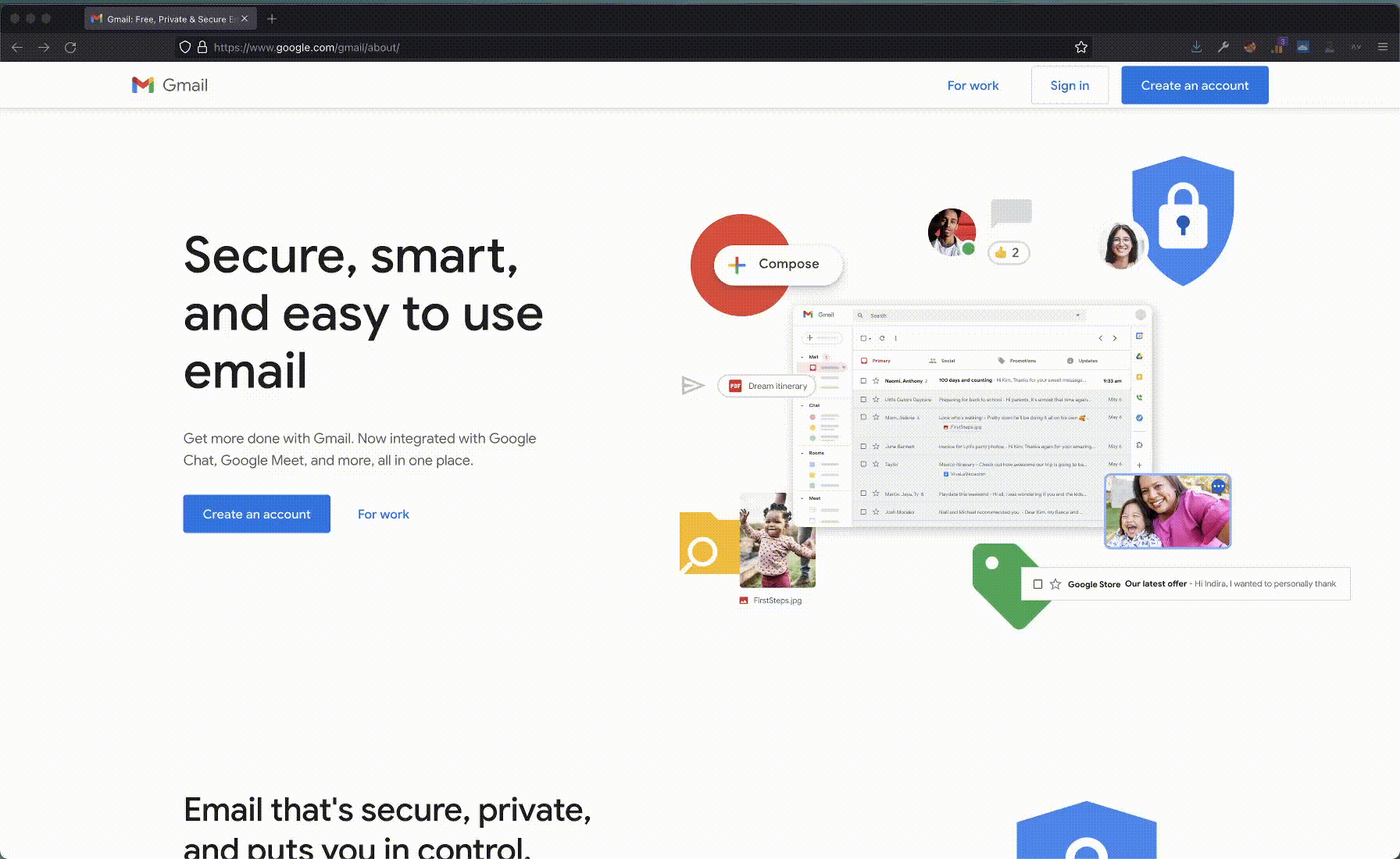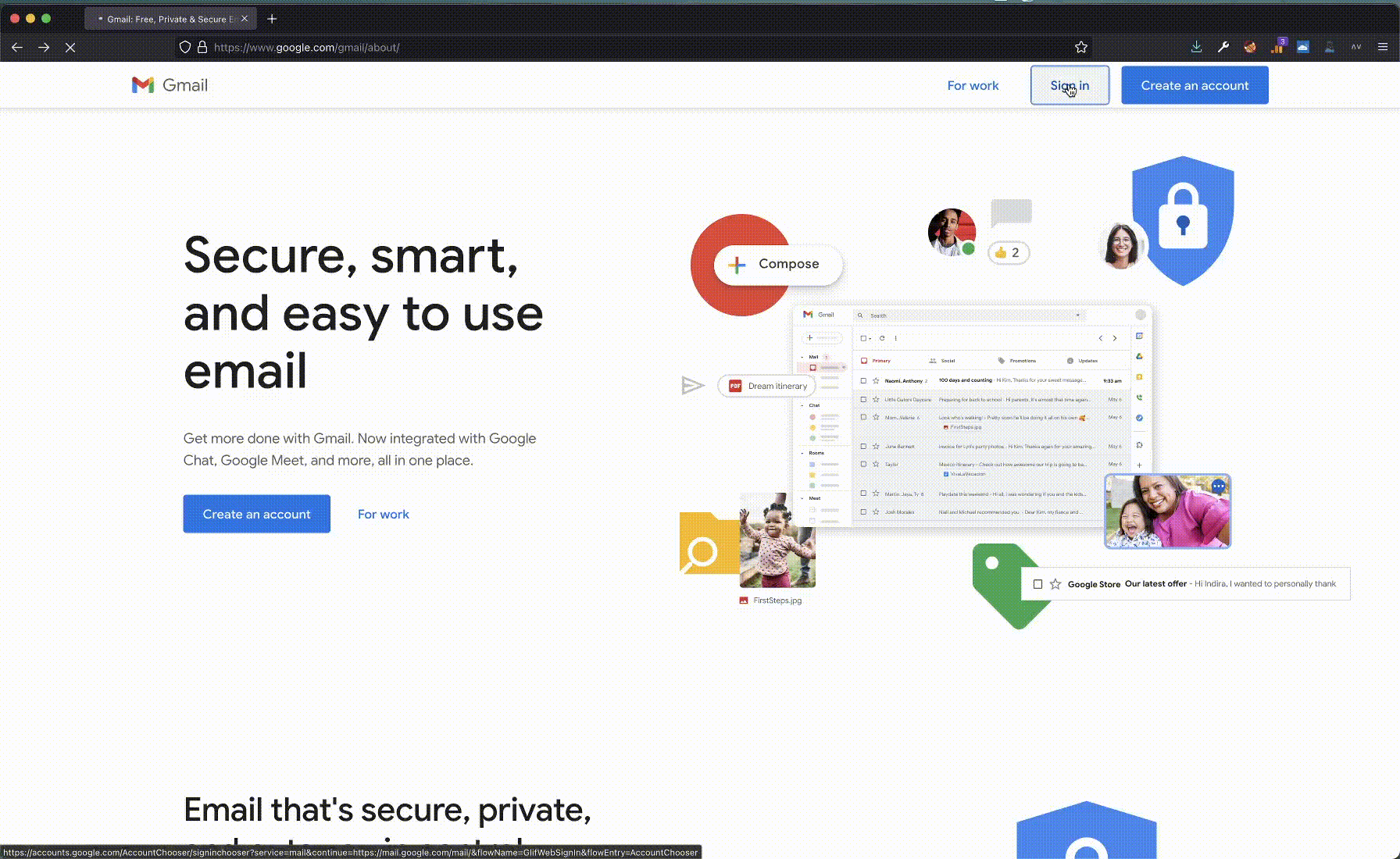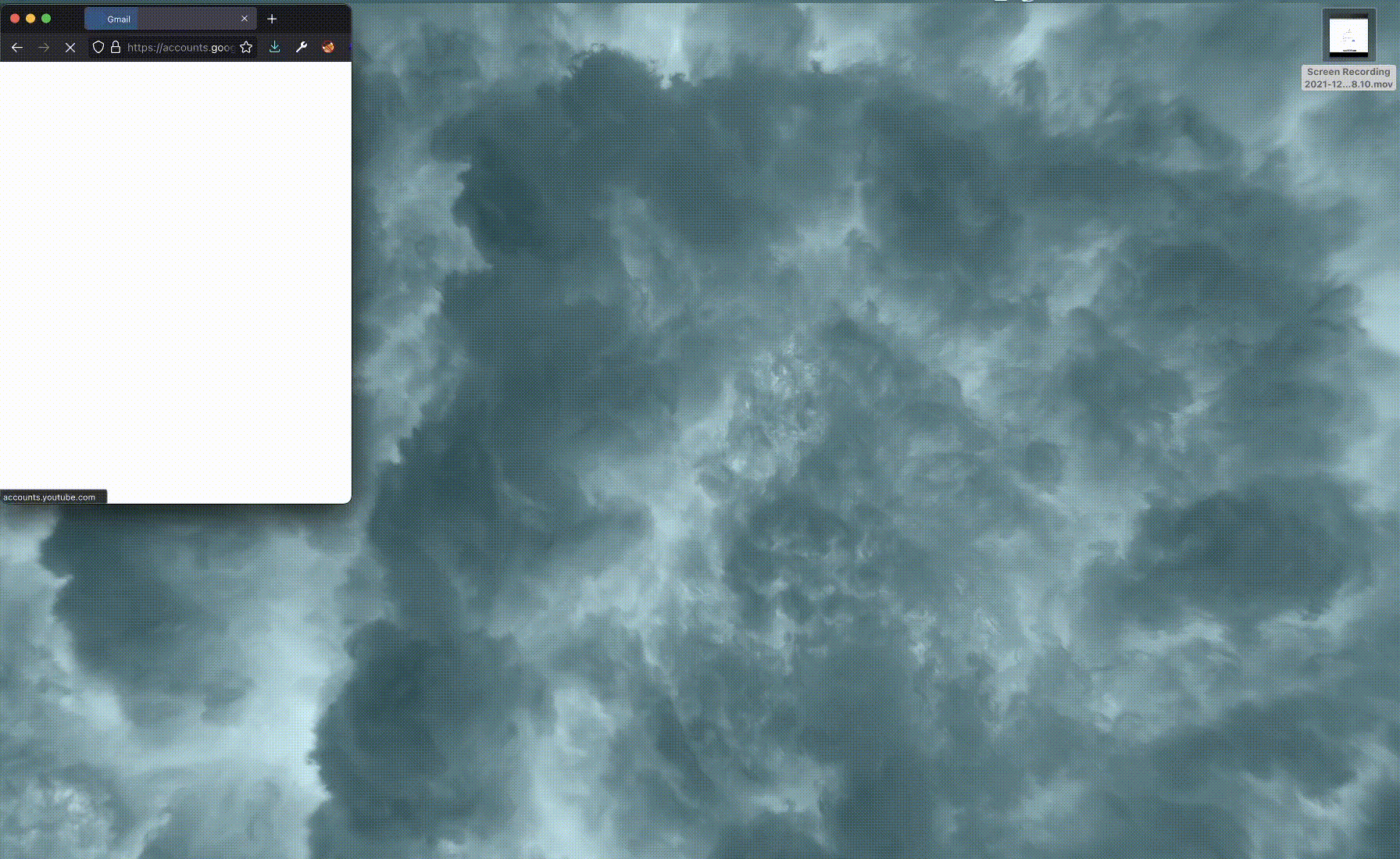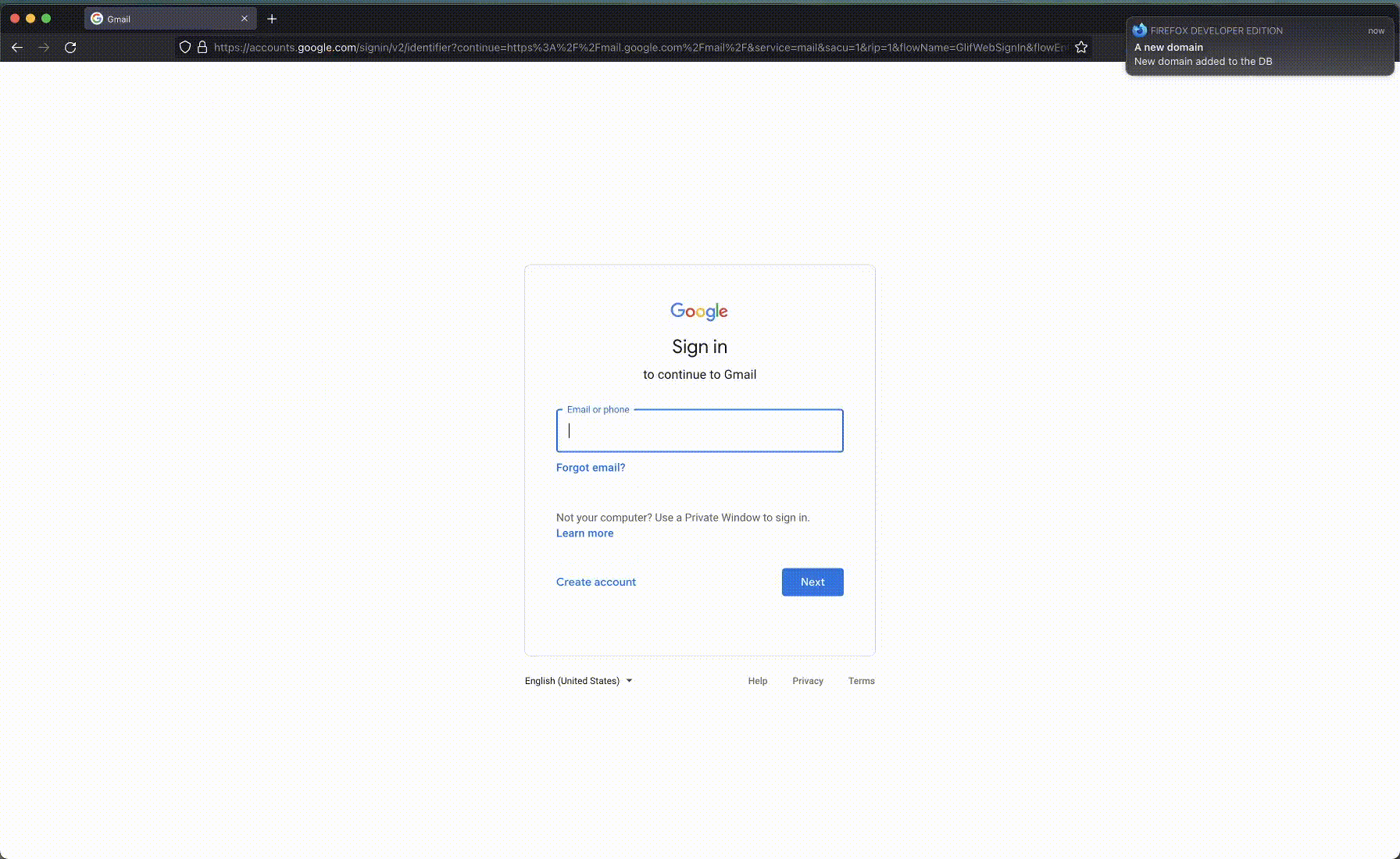
We discussed other potential solutions to the resolution and size challenge, and each has its pros and cons:
Mobile-only
Allow the extension to work only on mobile devices.
Fewer resolution differences (might still need some resizing)
Mobile-only
Inject JavaScript
The extension can inject JavaScript code that resizes only the visible page instead of the whole browser window.
Less flickering
More performant
Cross-origin issues
Render the page in an iframe
By creating a new iframe with a 1x1 size, we can draw the page and take a screenshot without the user even noticing it.
Invisible to the user
Requests are doubled.
What the user sees would not be the same as what Hominoid sees.
Complex to implement.
Delete margins
By using image recognition, algorithms we could remove the margins that the pages add to compensate for different resolutions.
Invisible to the user.
Very complex to implement.
It won’t work on responsive pages which fill the margins with content.
It won't work on several marginal cases (pun intended). Might be impractical.
Custom browser
We could fork the attempt to use Chromium and solve this issue at the core of the browser.
Invisible to the user.
Extremely performant.
Extremely complex to implement.
Cannot work on any other browser.
Notifying The User
After performing the comparisons, Hominoid needs to inform the user of its results. We use operating system notifications for three types of potential notifications.
- If the URL and fingerprint are new, the signature is added to the local database and the user is alerted.

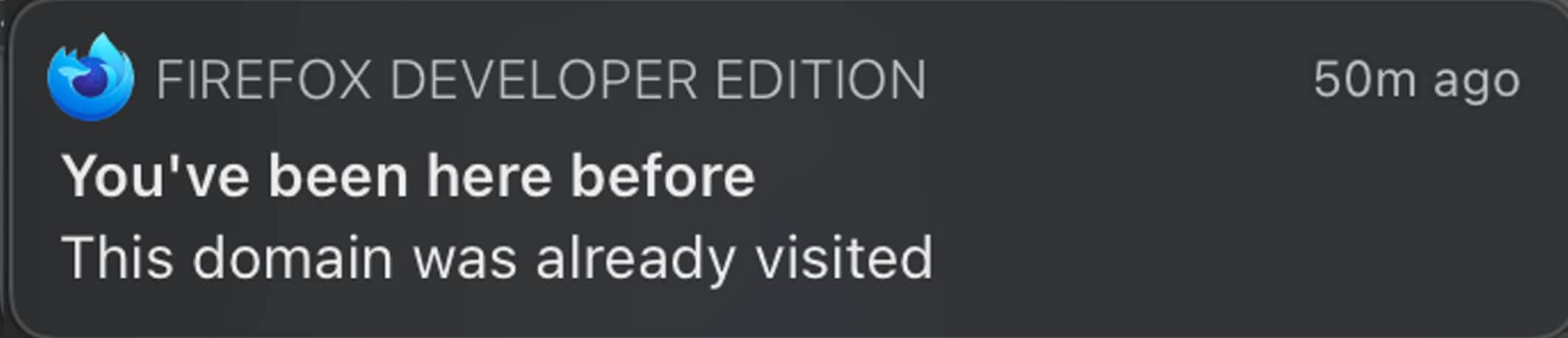
- If it is similar, but it belongs to the same domain, everything is safe and the user is alerted that the domain has been added to the local database.
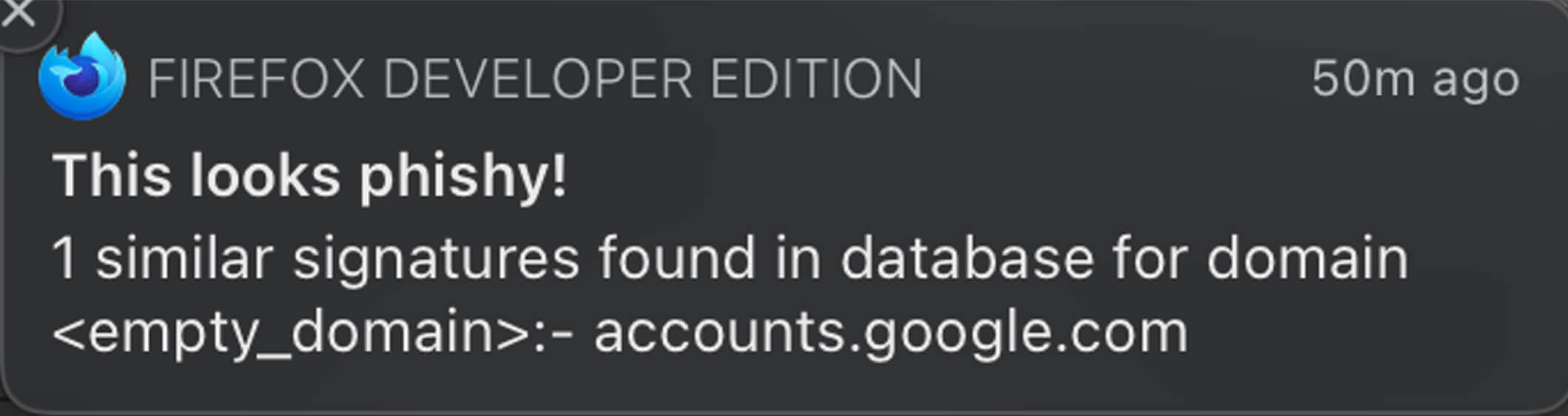
- If the signature belongs to another domain, the user is warned about a potential phishing attempt.

At first, we compared individual pages instead of domains. That means that we enforced the full URL of the current page to match the one stored in the database, otherwise we would consider it a phishing attack. But we realized it does not make a lot of sense. Sites usually add or remove parameters from their URLs so they are not always exactly the same. So we simplified it and only store pairs of {domain, signature} rather than {exact URL, signature}.
Bringing It All Together
Now that we know what Hominoid does, we can examine the workflow. On every page load Hominoid, performs these five steps:
- Resizes the browser window
- Takes a screenshot
- Calculates the screenshot signature
- Verifies the signature and domain against the local database
- Notifies the user of the outcome
Here is a full demo of the extension working:
Future Work
On the technical side we found several challenges that need to be addressed.
Besides fixing the resizing and resolution problem, we would also like to set custom configuration rules to allow the extension to run only on certain pages and ignore the rest, as we might not be interested on checking if a static site with no user input is a phishing site. We could check for certain input fields or URLs. Think of only running the extensions logic on login pages.
Small changes on the sites might be tolerated by the Hamming Distance, but big re-designs of common sites would invalidate the database. Some way to clear it on a per-site basis might be needed as well.
Other Hamming Distance thresholds might be tested as well as different hashing algorithms. And some kind of controlled centralization could be added. For example, having a company-wide database that has a list of valid signatures so every client can sync with it. It would still allow users to control what goes in their database instead of a fully-centralized solution like those existing nowadays.
Conclusion
We've proven that perceptual hashing algorithms can be used on a small scale to detect phishing sites. So, is this a silly proof of concept? We'll let you decide.
References
- Google Chrome’s unsafe sites: https://support.google.com/chrome/answer/99020
- A deeper explanation on perceptual hashing algorithms: